This is very much a work in progress, and in fact I suspect it's not even the latest version, but hopefully at least it's more useful up here than on my hard drive, even in a very draft-ish state.
February, 2010.
This is a thoughts-in-development piece on how the Science Museum/NMSI could provide re-usable, interoperable, structured machine-readable data for use as linked data or APIs.
I've made it a document rather than a blogging it on http://openobjects.blogspot.com/ or putting it on http://museum-api.pbwiki.com/ directly because it's a bit too long (and probably a bit too incoherent) right now. I'd love to hear your thoughts though - twitter (http://twitter.com/mia_out) or as comments/edits here.
URIs and concepts we could model
Concepts we could model:
- objects,
- types of objects,
- people/organisations,
- events,
- places,
- narratives (stories, themes, topics - typically more subjective, contextualised, interpretive),
- science subjects (science-y concepts like physics, chemistry, engineering, maths, psychology, astronomy)
- news stories
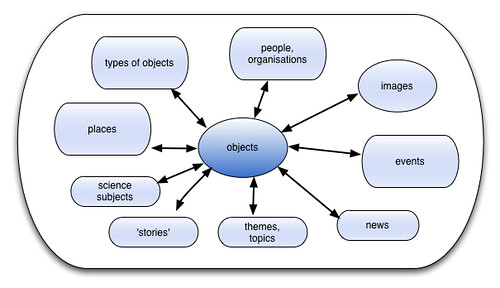
Each of these would form part of a URI e.g. http://sciencemuseum.org.uk/objects/[identifier]
I'm including here things that we generally have enough information about for it to make sense for us to link them. I'll talk about ways to link to the rest of the world below.
Objects - we have lots of these. Yay! Each record is about a specific accessioned object. As you can see from the diagram above, objects can be related to everything else (and to each other, in various ways). An object might be as big and iconic as Robert Stephenson's Rocket or as small as a spark plug.
Types of objects - a more generic view. It allows us to solve two problems - our collections don't cover everything we want to talk about, and we have lots and lots of certain types of objects. So a page on spark plugs is a user-friendly layer of content about spark plugs for general readers and provides links to all 8000 spark plugs in the collection (I totally made that number up).
It lets us discuss topics that our collections don't cover comprehensively, and to create a user-friendly layer between the detail of our collection (8000 spark plugs) and general information about spark plugs.
[If you're not familiar with museum collections - coverage varies according to what was collectable or collected - our collections may represent fashions in history of collecting more than an ideal uber-collection. Unlike, say, an art gallery, not every single item in our collection is a precious and unique diamond - for the general user, it might be enough to know what we have some information about dental forceps and a picture of one - but for the specialist researcher, browsing our collection of 300 of them might be the highlight of their week. (Maybe).]
Places - in our collections databases, we can look at the place an object was made, used, designed, destroyed, collected, restored, redesigned, invented, etc, etc. People and events also have various possible relationships to places.
People/organisations - ideally, we'd like to Wikipedia for every person and place, but not everyone we refer to in our collections has Wikipedia notability.
Images - we also have lots of related images, which are a major asset but work better in relation to other things (like objects) than as concepts on their own.
Other hooks in our content include dates and materials - these might be particularly useful for facetted browsing or mashups made with our data, but don't particularly make sense as concepts on their own. We also produce contemporary science news through our (re-opening in June) Antenna gallery, and marking this up with hNews seems a no-brainer. Working out how to link to the original news stories, whether in Nature, the BBC, whatever, would be good - something we can build into the publishing platform (WordPress MU) to make it nice and easy for our content authors would be even better.
Linking concepts and microsites, creating a canonical object home
I'm proposing a model that should allow us to make the most of all the data we've got online already as well as designing around concepts. [see notes below for some background]
As well as 'objects' as a basic concept, museums come with a handy set of stable concepts built into our collections management systems. Sometimes these are called 'subject authorities'. They cover things like people and organisations, places, events and the relationships between them. We often build various interpretative narrative layers on top of them - themes, topics, stories, whatever.
If we build permanent URIs around those concepts, we can link to them from the existing microsites. We can also wrap metadata around the elements already on the pages of those microsites so that the data is meaningfully machine-accessible in situ.
As an example, we'd have http://sciencemuseum.org.uk/objects/1956-152 as the 'home page' for the Pilot ACE computer in our collection. This page would contain the basic 'tombstone' information - when, where, what, etc, and link to every known instance of the object in other sites, as below. These other sites might be exhibitions, subject-specialist sites, cross-institution collections. Often they'll contain information written specifically for that site, particularly tailored for its scope and audiences.
This object is represented in various microsites. The image below shows up we might mark up those sites with links to our Science Museum concepts:
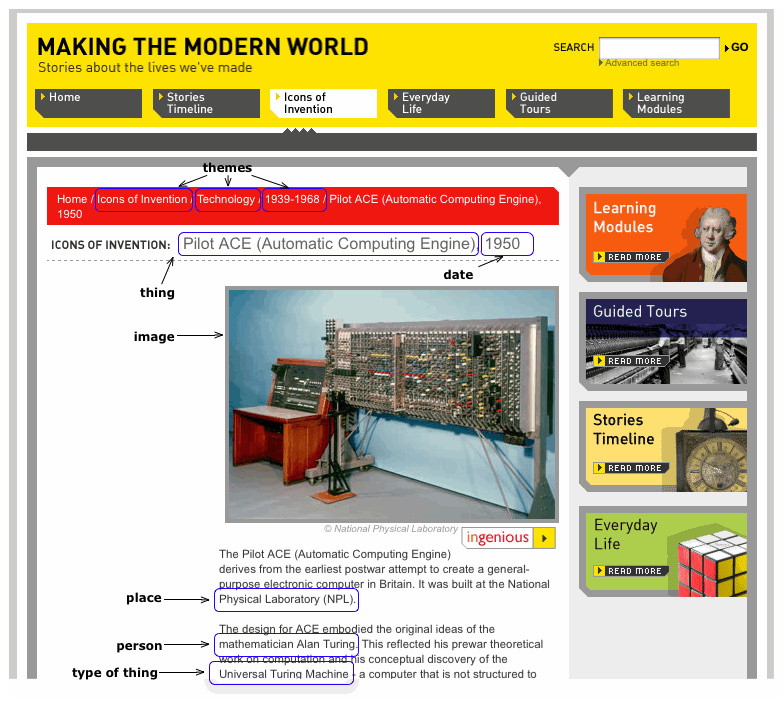
The object home page could also link to the Pilot Ace page on Ingenious and on our Centenary site, and they could link back to the object home. They could also link to our Alan Turing page, National Physical Laboratory page, etc.
It'd be great if we could link to other content about that object - this BBC article on Pilot ACE is a pointer to more content.
Vocabularies
This is one of the places I get stuck... Do we go general or specific? There's lots of stuff out there for visual resources but that doesn't describe our collections well. There's some discussion of this on various pages here, including Authority Lists, Implementation formats, and RDFa (the names get out of control fairly quickly!).
Notes on URIs
Some of our accession numbers are going to make things difficult because they contain '/'.
The objects we currently have online in this format are divided by collection, which is possibly a less permanent concept, so my preference would be for http://www.sciencemuseum.org.uk/objects/1878-3 rather than http://www.sciencemuseum.org.uk/objects/computing_and_data_processing/1878-3 (1873-3 is the accession or inventory number - these are about as permanent an identifier as you can get [insert museum-y discussion of the exceptions]).
Background-y bits
On Wednesday [you can tell how long ago I started this because that was February 24] I went to the second London Linked Data meetup, held during dev8D.
For a while I've been wondering what we (Science Museum/NMSI) could do with linked data, but it's also taken a while for the issues to bubble up.
The first two issues are data standards and vocabulary. As the saying goes, 'the good thing about standards is that there are so many to choose from'. http://museum-api.pbworks.com/Implementation-formats and http://museum-api.pbworks.com/RDFa bear witness to the difficulties of... finding out what developers prefer to work with (if they care at all), finding out what other museums can output to try and get some critical mass going...
The third is machine-readable interface design. Tom Scott [Apis and APIs] advocates building APIs so that you're linking people to the concepts that matter to them, and making your website your API. I think this is the right way to go, but it's made trickier by the fact that we're not a greenfield site - we've got exhibition microsites that are over ten years old. We're gradually migrating all that data into a central repository, but it'd be good if we could make the data already online in those sites re-usable too.
Other earlier notes... When designing the Cosmic Collections API last year, I'd considered building it into the 'human-facing' website architecture, so that a device could request XML or JSON versions of the pages alongside the (X)HTML pages. In the end I went for a standalone API as an interim solution. The Cosmic Collections competition was designed in part to answer some of my questions about the formats preferred by developers.
Comments (18)
Mia said
at 3:02 pm on Mar 21, 2010
Wow - I only tweeted this a few minutes ago and I've had lots of useful feedback.
Jim suggested 'collections' as a concept (http://twitter.com/pekingspring/statuses/10821178733) and he's absolutely right. It'd be great to be able to link our King George III collection (http://www.sciencemuseum.org.uk/onlinestuff/stories/the_king_george_iii_collection.aspx) with that at the British Library (http://www.bl.uk/reshelp/findhelprestype/prbooks/georgeiiicoll/george3kingslibrary.html)
This made me realise I've also completely missed out 'exhibitions' as a concept - we do cover this for current exhibitions to an extent, but there's a lot of information hidden in the choices made for previous exhibitions that could be useful. It also contributes to really making the object home the definitive resource.
Mia said
at 3:06 pm on Mar 21, 2010
Tony (http://twitter.com/psychemedia/statuses/10821277577 http://twitter.com/psychemedia/statuses/10821106102) also suggested 'there's also the design of BBC URI sets; eg if you take a programme episode to be an object, does that lead anywhere?', which is something I'd been thinking about - I really need to finish writing up my notes from the London linked data meetup; and using http://writetoreply.org/ukgovurisets/ 'as a framework for museum/collections URI sets?' - which I hadn't even known about, but will read up on.
Mia said
at 5:39 pm on Mar 21, 2010
More comments:
DavidHaskiya (http://twitter.com/DavidHaskiya/status/10824735162) suggested 're vocabularies:General ones e.g. Geonames, LCSH, VIAF should work for you. A science object theaurus you'll have to do yourselves!' (http://en.wikipedia.org/wiki/Library_of_Congress_Subject_Headings http://www.oclc.org/research/activities/viaf/default.htm)
Wilbert Kraan (http://twitter.com/wilm/statuses/10823953962) suggested 'I'm not an expert in cultural heritage, but CIDOC seems a good, rdf based ontology to adopt or plunder http://cidoc.ics.forth.gr/'
Mia said
at 7:20 pm on Mar 21, 2010
And another comment - can you tell I should be doing something else today? It's all about constructive procrastination.
Richard Morgan from across the road at the V&A commented (http://twitter.com/rmorg/status/10831225400), 'linked data vocabularies tricky for me too. For V&A I'm tending towards just geo, foaf and dbpedia - more about links than data' which I think is a useful perspective. There is a level at which the precise application of term lists matters, but if it means we spend the next ten years trying to get it perfect rather than doing something now, I'd rather we did something now. The two aren't mutually exclusive technically, but pragmatically I only have limited time/brain space in which to get something done.
andy.powell@... said
at 2:14 pm on Mar 22, 2010
Mia,
hi... I think you'll need to model both real-world objects and web documents as part of this. So, for example... for any particular artefact, say the lunar lander, you have the thing itself (a real-world object which is assigned one URI) and the description of that thing (a Web document which is assigned a different URI).
To get from the 'object' URI to the 'description' URI requires an HTTP 303 redirect response (unless you choose to use hash URIs).
The 'description' URI can offer multiple representations, e.g. HTML with embedded RDFa and RDF/XML.
So, if http://sciencemuseum.org.uk/objects/1956-152 is the URI of a real-world object then it does NOT directly serve a representation of that object. Rather, it issues a 303 redirect to a URI that serves representations of that object, e.g. http://sciencemuseum.org.uk/documents/1956-152.
Apologies if you knew this already and I missed it above. I think this applies to most of the entities in the diagram above.
andy.powell@... said
at 2:19 pm on Mar 22, 2010
Sorry... I should have said, "Rather, it issues a 303 redirect to a URI that serves representations of a description of that object, e.g. http://sciencemuseum.org.uk/documents/1956-152.".
Bill Roberts said
at 2:22 pm on Apr 5, 2010
I like your list of "URIs and concepts we could model" and the idea of how the web page about an object in the collection can be linked to relevant people, places, images etc.
There's a lot of scope for this approach to help people to explore the collection from different perspectives and via different dimensions.
Vocabularies: this is an area where it makes sense to re-use existing work where possible, but if there is nothing out there that fits your purpose, don't be afraid to invent a new specialist vocabulary of your own. It's easy (and normal practice) to 'mix and match' terms from multiple vocabularies/ontologies as required.
Mia said
at 6:23 pm on Apr 9, 2010
Thanks for your really useful comments, Bill. I've been horribly busy preparing for a conference next week but will respond properly when my feet are back on the ground!
John S. Erickson, Ph.D. said
at 7:16 pm on Apr 13, 2010
This is an excellent start!
Try to keep in mind that an important reason for publishing the museums artifacts, whether real or digital, is to enable data about them to be "meshed" with other data (from the museum and from elsewhere) and republished, possibly in unanticipated ways, and the "mashed" applications that are created from those datasets. So the answer to whether you are doing it "correctly" will depend on the feedback you get!
The most important thing for you to do is ensure that you make it easy for your community of users to provide you with feedback, wiki a wiki or whatever. Make sure this is obvious and easy, AND that you adapt as they provide that feedback!
You might consider using OpenVocab http://open.vocab.org/ as a means for your community to add new terms.
Good luck!
John
Raj said
at 11:51 pm on Apr 15, 2010
There's already a great authoritative reference for places:
GeoNames Ontology
http://www.geonames.org/ontology/
"over 6.2 million geonames toponyms now have a unique URL with a corresponding RDF web service"
eatyourgreens said
at 11:40 am on Apr 16, 2010
Descriptions depend on context, so might need their own URLs, separate from objects. A record typically has a description that's written for the collections management system
eg. http://www.nmm.ac.uk/collections/explore/object.cfm?ID=BHC0719 but a short label when the object is on display eg. http://www.nmm.ac.uk/visit/exhibitions/past/turmoil-and-tranquillity/gallery/?item=51
Eric Kansa said
at 5:54 pm on Apr 17, 2010
Great discussion of the linked data issues.
I think we can add a point that a RESTful web services (esp. based on simple common standards like Atom) can be useful for bridging between more "Plain Web" design approaches and linked data approaches. Here's a<a href='http://www.alexandriaarchive.org/blog/?p=497'> paper</a> I gave at the Computer Applications in Archaeology conference about this issue.
Eric Kansa said
at 5:55 pm on Apr 17, 2010
OK. Try this again, since HTML doesn't work in the comments.
Great discussion of the linked data issues.
I think we can add a point that a RESTful web services (esp. based on simple common standards like Atom) can be useful for bridging between more "Plain Web" design approaches and linked data approaches. Here's a(http://www.alexandriaarchive.org/blog/?p=497) I gave at the Computer Applications in Archaeology conference about this issue.
Richard Light said
at 12:08 am on Jul 8, 2010
Notes on 7 July 2010 meetup (part 1)
These thoughts are my own "take homes" from the discussion, rather than any sense of the meeting's overall conclusions.
What data do museums have?
Database content, mostly fielded and designed mainly for collections management support. Textual materials, much of it in a
non-accessible "grey literature" format. Images.
The database content is typically (reasonably) self-consistent within a given environment. Thus we have known properties (from the field name) with usable string values. The challenge from a Linked Data perspective is the cost-effective generation of URLs from the string values currently held, e.g. for people and places, given that different museums will have different vocabularies to control their content.
Who wants to use this data?
The public, who are typically interested in classes of objects (rather than individual objects), or in objects with certain properties (e.g. coming from a place of interest to them). Educators, or more specifically people who create resources for educators to use. Students, if relevant objects could be easily accessed as "follow up" to formal learning materials.
Richard Light said
at 12:09 am on Jul 8, 2010
Notes on 7 July 2010 meetup (part 2)
How do we improve the data?
There is nothing to stop every museum publishing URLs, and whatever associated Linked Data they have to hand, for each object in their own collection, and thereby giving them a "hook" onto which others can hang added-value information and assertions of their own. They should treat this task as an urgent priority.
Where possible, convert string values in data to URLs, ideally widely-used (not just local) ones. Could use e.g. geonames.org for place names, or dbpedia for object class names. Interest in Portsmouth's historical gazetteer for "old" place names.
There is a clear need for a sector-specific ontology which represents the properties found, i.e. the types of information recorded in
museum databases. This will act as the "predicate" in Linked Data triples/assertions. It could be based on an existing agreement
about these semantics, e.g. CIDOC CRM or LIDO.
Axis-based data such as geographical co-ordinates or dates/date ranges could be treated as purely numerical data, or "pixellated" by assigning a URL which imposes a certain level of precision (e.g. year for dates). Or both approaches could be adopted.
What's the museum take on Linked Data?
Simple assertions are not enough; we care about the attribution of those assertions (i.e. who is making the assertion). We also want a framework which allows the expression of uncertainty and doubt.
We are not particularly bothered about the specific format (RDF/XML, RDFa, JSON, Topic Maps) in which Linked Data is published, but we would like to be able to "do the job once" and have done with it.
Joshan Mahmud said
at 12:18 am on Jul 8, 2010
Thanks for the minutes Richard - seems like it was a really interesting discussion - shame I couldn't be there - particularly as we've been working with the author of CIDOC to start mapping our data! Look forward to the next meeting. Josh
Shaun Osborne said
at 4:28 pm on Jan 28, 2011
hi Mia
I been wondering about identifiers, pref. UUID types
this sort of fits in where you have [insert museum-y discussion of the exceptions] in your doc.
given we have loads of object numbers full of illegal characters (for both file systems and URIs) I thought the concept of MuseumID may be very helpful as we moved toward linked data..
http://museumid.net/about
Mia said
at 11:21 pm on Jan 31, 2011
Hi Shaun, that's a really interesting proposal, thanks for sharing the link. Do you know wherther ICOM would support it and guarantee permanence?
Cheers, Mia
You don't have permission to comment on this page.